using CitableBase, CitableText
engraving_text = CtsUrn("urn:cts:citeusnatarch:foundingdocuments.declindep.engraving:")
original_text = CtsUrn("urn:cts:citeusnatarch:foundingdocuments.declindep.original:")A walkthrough: the American Declaration of Independence
See versions of Julia packages used on this page
This page was compiled with the following versions of the packages illustrated here:
- CitableBase 10.4.0
- CitableCorpus 0.13.5
- CitableImage 0.7.2
- CitableObject 0.16.1
- CitablePhysicalText 0.12.1
- CitableTeiReaders 0.10.3
- CitableText 0.16.2
- EditionBuilders 0.8.5
- OrderedCollections 1.8.1
- Orthography 0.22.0
- StatsBase 0.34.5
- VectorAlignments 0.3.0
Background and sources
The historian and classicist Danielle Allen offers a new interpretation of the American Declaration of Independence that is literally based on a new reading: she punctuates the text differently from most printed editions. (See her book (D. S. Allen 2014) and the subsequent manuscript available from the Institute for Advanced Study (D. Allen 2015).)
This page briefly illustrates how we could apply the Julia packages for citation and for working with digital texts to the problem of reading the text of the Declaration.
Sources
- The U.S. National Archives has published freely available, high-resolution images of both the original signed parchment, and a widely used engraved reproduction. (See the presentation of the Declaration of Independence from the National Archives, with links to downloadable images) These images have been added to the Homer Multitext project’s citable image service.
- Two transcriptions of the text in TEI-compliant XML are included in this site’s github repository:
- transcription 1: a transcription of the text of the engraving, taken from this page of the National Archives web site
- transcription 2: a transcription of the text from the image of the original parchment
- The relations of text, pages and documentary image are documented in a delimited-text file in this site’s github repository here.
Citation with URNs
Learn more about scholarly citation with URNs
Citing texts
Cite the text of the original and the engraving using CtsUrns with different version identifiers.
Learn more about citation with
CtsUrns
Citing objects
Identify a collection of pages (front and back) for the original and for the engraving using Cite2Urns.
using CitableObject
engraving_pages = Cite2Urn("urn:cite2:citeusnatarch:declindep.engraving:")
original_pages = Cite2Urn("urn:cite2:citeusnatarch:declindep.original:")
Learn more about citation with
Cite2Urns
Citing images
Identify documentary images for the front of the parchment and the first page of the engraving using Cite2Urns.
original_img1 = Cite2Urn("urn:cite2:citeusnatarch:declindep.v1:Declaration_Pg1of1_AC")
engraving_img1 = Cite2Urn("urn:cite2:citeusnatarch:declindep.v1:Declaration_Engrav_Pg1of1_AC")Digital texts
Orthography
Define an orthographic system for the texts we will read.
using Orthography
ortho = simpleAscii()
Learn more about orthography
Create citable texts
Read the XML source from a URL, and make the marked-up content accessible through canonical citation with the CitableTeiReaders package.
using CitableTeiReaders
engraving_url = "https://raw.githubusercontent.com/neelsmith/quart-home/main/walkthrough/adoi/declaration_engraving.xml"
engraving_corpus = readcitable(engraving_url, engraving_text, TEIAnonblock, UrlReader)
original_url = "https://raw.githubusercontent.com/neelsmith/quart-home/main/walkthrough/adoi/declaration_original.xml"
original_corpus = readcitable(original_url, engraving_text, TEIAnonblock, UrlReader)Compose a univocal diplomatic edition from the multivalent XML document with the EditionBuilders package.
using EditionBuilders
builder = MidDiplomaticBuilder("Diplomatic edition buidler", "dipl")
engraving_dipl = edited(builder, engraving_corpus; edition = "engraving_dip")
original_dipl = edited(builder, original_corpus; edition = "original_dipl")
Learn more about creating citable texts
A full digital scholarly edition
Collect relations of text, image and artifact
Read records relating text, image and artifact using the CitablePhysicalText package.
using CitablePhysicalText
delimited_url = "https://raw.githubusercontent.com/neelsmith/quart-home/main/walkthrough/adoi/declaration.cex"
triplesets = fromcex(delimited_url, DSECollection, UrlReader)
Learn more about modelling physical texts.
Services for images
Configure the Homer Mulitext project’s image service using the CitableImage package.
using CitableImage
imgbaseurl = "http://www.homermultitext.org/iipsrv"
imgroot = "/project/homer/pyramidal/deepzoom"
imgservice = IIIFservice(imgbaseurl, imgroot)
Learn more about citable image services
Application: explore differences in the texts visually
TBA
First, we’ll find passages where the two editions differ. One way to focus our attention on differences in content rather than formatting is to compare tokenizations of each text. The following function compares two citable text passages by tokenizing each and comparing the result.
using CitableCorpus
"""True if text content of tokens in two citable passages matches."""
function tokensmatch(psg1::CitableCorpus.CitablePassage, psg2::CitableCorpus.CitablePassage, orthography::OrthographicSystem)
tkns1 = tokenize(psg1,ortho)
tkns2 = tokenize(psg2,ortho)
text1 = map(t -> t.passage.text, tkns1)
text2 = map(t -> t.passage.text, tkns2)
text1 == text2
endNext we use the function to find parallel passages where the texts differ.
@assert length(original_dipl) == length(engraving_dipl.passages)
difflist = []
for (orig,dipl) in zip(original_dipl.passages, engraving_dipl.passages)
if ! tokensmatch(orig,dipl,ortho)
push!(difflist,(orig,dipl))
end
endLook in appropriate set of triples:
triplesets[1] |> label"Collection of DSE records for the stone engraving of the American Declaration of Independence"triples_engraving = triplesets[1]
triples_original = triplesets[2]Now find images
(psg1_orig, psg1_engraving) = difflist[1]
imgs_orig = imagesfortext(psg1_orig.urn, triples_original; keepversion = false)
imgs_engraving = imagesfortext(psg1_engraving.urn, triples_engraving; keepversion = false)[ Info: Txt urn:cts:citeusnatarch:foundingdocuments.declindep.original_dipl:2
[ Info: Look for txturn urn:cts:citeusnatarch:foundingdocuments.declindep:2
[ Info: Txt urn:cts:citeusnatarch:foundingdocuments.declindep.engraving_dip:2
[ Info: Look for txturn urn:cts:citeusnatarch:foundingdocuments.declindep:21-element Vector{Cite2Urn}:
urn:cite2:citeusnatarch:declindep.v1:Declaration_Engrav_Pg1of1_AC@0.03594,0.1768,0.9243,0.1439Display the result on this web page!
ict = "http://www.homermultitext.org/ict2/?"
img_md_original = linkedMarkdownImage(ict, imgs_orig[1], imgservice; w=600, caption="Passage in original")
img_md_engraving = linkedMarkdownImage(ict, imgs_orig[1], imgservice; w=600, caption="Passage in engraving")
"""
$(img_md_original)
$(img_md_engraving)
""" |> Markdown.parse
- manually use the Homer Multitext project’s Image Citation Tool to zoom in to more specific region of interest and cite it with a URN. Here we save references to the region of two images illustrating the word “Happiness.”
Manually explore, create two more detailed references.
happiness_engraving = Cite2Urn("urn:cite2:citeusnatarch:declindep.v1:Declaration_Engrav_Pg1of1_AC@0.4672,0.1935,0.07188,0.01804")
happiness_original = Cite2Urn("urn:cite2:citeusnatarch:declindep.v1:Declaration_Pg1of1_AC@0.4765,0.1892,0.07596,0.01857")
detail_md_original = linkedMarkdownImage(ict, happiness_original, imgservice; w=600, caption="Passage in original")
detail_md_engraving = linkedMarkdownImage(ict,happiness_engraving, imgservice; w=600, caption="Passage in engraving")
"""
$(detail_md_original)
$(detail_md_engraving)
""" |> Markdown.parse
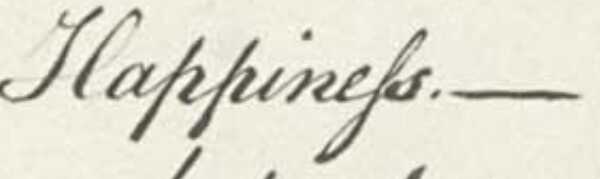
Application: organize differences in the texts as a sequence alignment
TBA
Learn more about citable text corpora
using VectorAlignments
tkns1 = split("Now is the time")
tkns2 = split("Now is a time")
featurematrix(tkns1, tkns2)5×2 Matrix{Any}:
"Now" "Now"
"is" "is"
"the" nothing
nothing "a"
"time" "time"
Learn more about sequence alignments
Application: basic vocabulary frequency
It is straightforward to find the vocabulary of a citable corpus with a known orthography.
tkns = tokenize(original_dipl, ortho)
lex = filter(tkn -> tokencategory(tkn) isa LexicalToken,tkns)
vocab = map(tkn -> tokentext(tkn), lex)1328-element Vector{SubString{String}}:
"In"
"Congress"
"July"
"The"
"unanimous"
"Declaration"
"of"
"the"
"thirteen"
"united"
⋮
"other"
"our"
"Lives"
"our"
"Fortunes"
"and"
"our"
"sacred"
"Honor"We can use the StatsBase package to count frequencies of items in a list, and can convert that dictionary to a sortable ordered dictionary with the OrderedCollections package.
using StatsBase, OrderedCollections
counts = countmap(vocab) |> OrderedDict
sort!(counts; byvalue = true, rev = true)OrderedDict{SubString{String}, Int64} with 576 entries:
"of" => 78
"the" => 76
"to" => 64
"and" => 55
"our" => 25
"for" => 20
"their" => 20
"has" => 20
"He" => 18
"in" => 18
"a" => 15
"them" => 15
"these" => 13
"by" => 13
"us" => 11
"have" => 11
"that" => 10
"all" => 10
"which" => 10
⋮ => ⋮Works cited
Allen, Danielle. 2015. “Punctuating Happiness.” https://www.ias.edu/sites/default/files/sss/pdfs/Allen/punctuating-happiness-2_12_15.pdf.
Allen, Danielle S. 2014. Our Declaration: A Reading of the Declaration of Independence in Defense of Equality. 1st edition. New York: Liveright.